- Zrozumieć System Plików EXT4
- Spis zagadnień do opanowania
- 1. Fundamenty: Po co nam system plików?
- 2. Architektura: Grupy Bloków i Superblock
- Struktura typowej Grupy Bloków:
- 3. Mechanika: I-węzły, bloki i ekstenty
- Ewolucja adresowania: Skalowanie dla plików różnych rozmiarów
- Ekstenty – ewolucja w EXT4
- 4. Logika: Jak Linux znajduje Twoje pliki?
- 5. Efektywność: Rozmiar bloku i slack space
- 6. Diagnostyka: Limity plików a miejsce na dysku
- 7. Niezawodność: Rola kroniki (Journaling)
System Plików EXT4 w Linux – Materiały Dydaktyczne
Zrozumieć System Plików EXT4
Przewodnik techniczny dla studentów informatyki – Budowa i działanie pod Linuxem
1. Fundamenty: Po co nam system plików?
Gdy spoglądasz na dysk twardy lub nowoczesny nośnik SSD, widzisz tylko sprzęt. Z perspektywy jądra systemu, taki nośnik jest jedynie gigantycznym ciągiem komórek pamięci, zwanych sektorami (LBA – Logical Block Addressing). Sektory te mają stały rozmiar, zazwyczaj 512 bajtów lub 4 kilobajty, i są po prostu ponumerowane od zera do wielu miliardów. Próba zapisania na takim nośniku „filmu z wakacji” bez żadnych zasad przypominałaby wrzucenie milionów luźnych kartek papieru do ogromnego, niepodpisanego worka.
System plików to właśnie ten system zasad, katalogowania i organizacji. Jest to warstwa oprogramowania, która tworzy dla nas zrozumiałą abstrakcję: zamiast prosić system o „odczytanie sektorów od 1 234 567 do 1 235 000″, prosimy o otwarcie pliku notatka.txt. System plików zajmuje się całą brudną robotą: wie dokładnie, na których fizycznych sektorach leżą dane tego konkretnego pliku, jak się on nazywa, jaki ma rozmiar i kto ma prawo do jego przeczytania.
Bez systemu plików system operacyjny nie potrafiłby odróżnić Twoich danych od danych innego użytkownika, ani nawet odróżnić końca jednego pliku od początku drugiego. Każdy plik posiada swoje metadane – to dodatkowe informacje „o informacji”, takie jak data ostatniej edycji, właściciel pliku czy flaga informująca, czy dany plik jest programem wykonywalnym. System plików dba, aby te metadane były zawsze spójne i bezpieczne.

2. Architektura: Grupy Bloków i Superblock
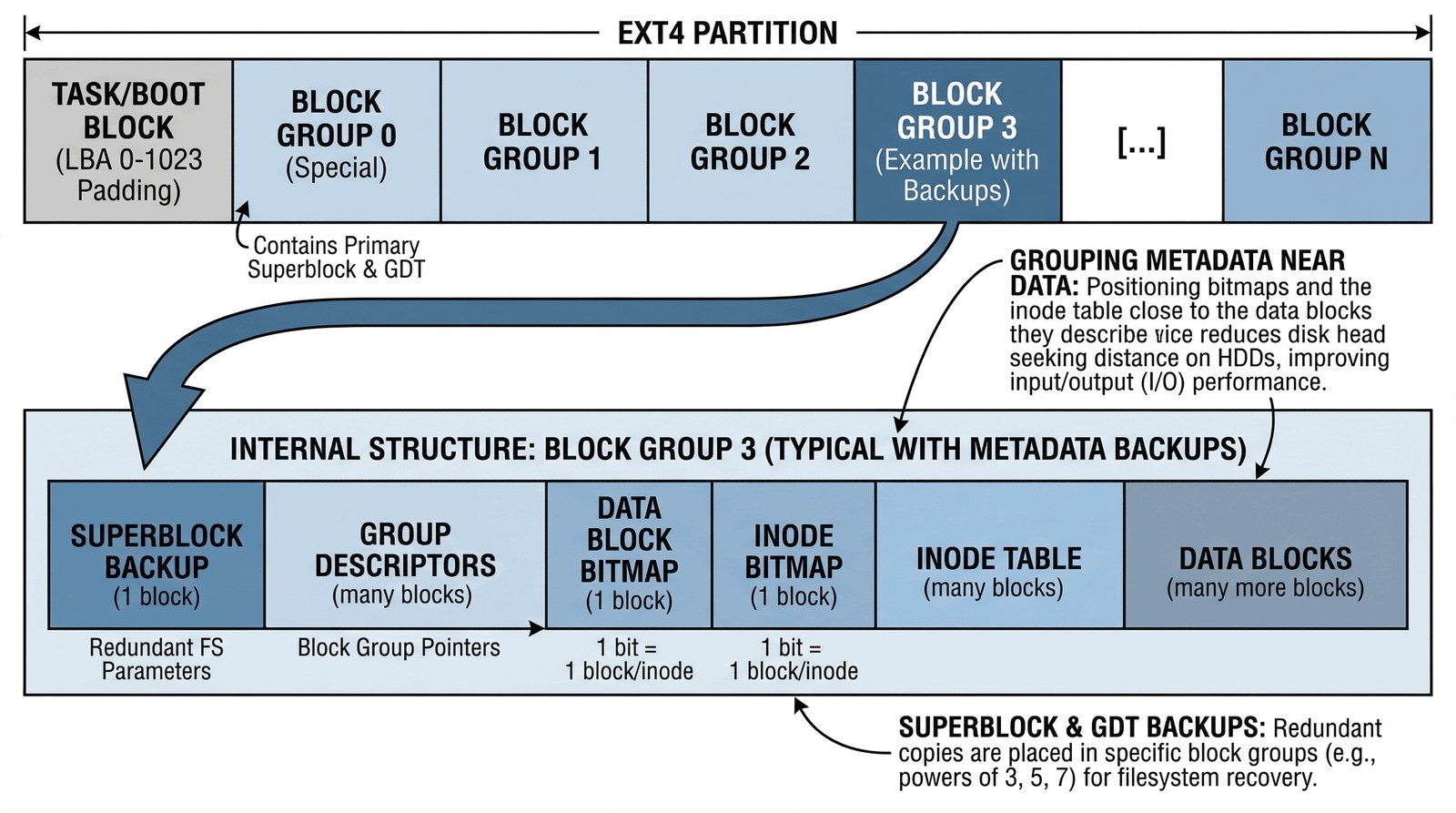
Współczesne systemy plików, takie jak EXT4, nie traktują partycji jako jednolitej masy. Aby uniknąć bałaganu i drastycznego spadku wydajności, cała dostępna przestrzeń jest dzielona na mniejsze, logiczne jednostki zwane Grupami Bloków (Block Groups). Można to porównać do budowy miasta podzielonego na dzielnice – każda dzielnica ma swoje własne sklepy, pocztę i urzędy, dzięki czemu mieszkańcy nie muszą jeździć na drugi koniec miasta po każdą drobną sprawę.
W świecie EXT4 oznacza to, że dane pliku oraz jego metadane (opis) są celowo zapisywane w tej samej Grupie Bloków. Ma to kluczowe znaczenie przede wszystkim dla dysków HDD, gdzie głowica fizycznie musi się przemieścić. Dzięki grupowaniu, głowica nie musi „skakać” po całej powierzchni talerzy, co przyspiesza odczyt. Każda grupa posiada swoją własną listę wolnych i-węzłów oraz wolnych bloków danych (tzw. Mapy bitowe).
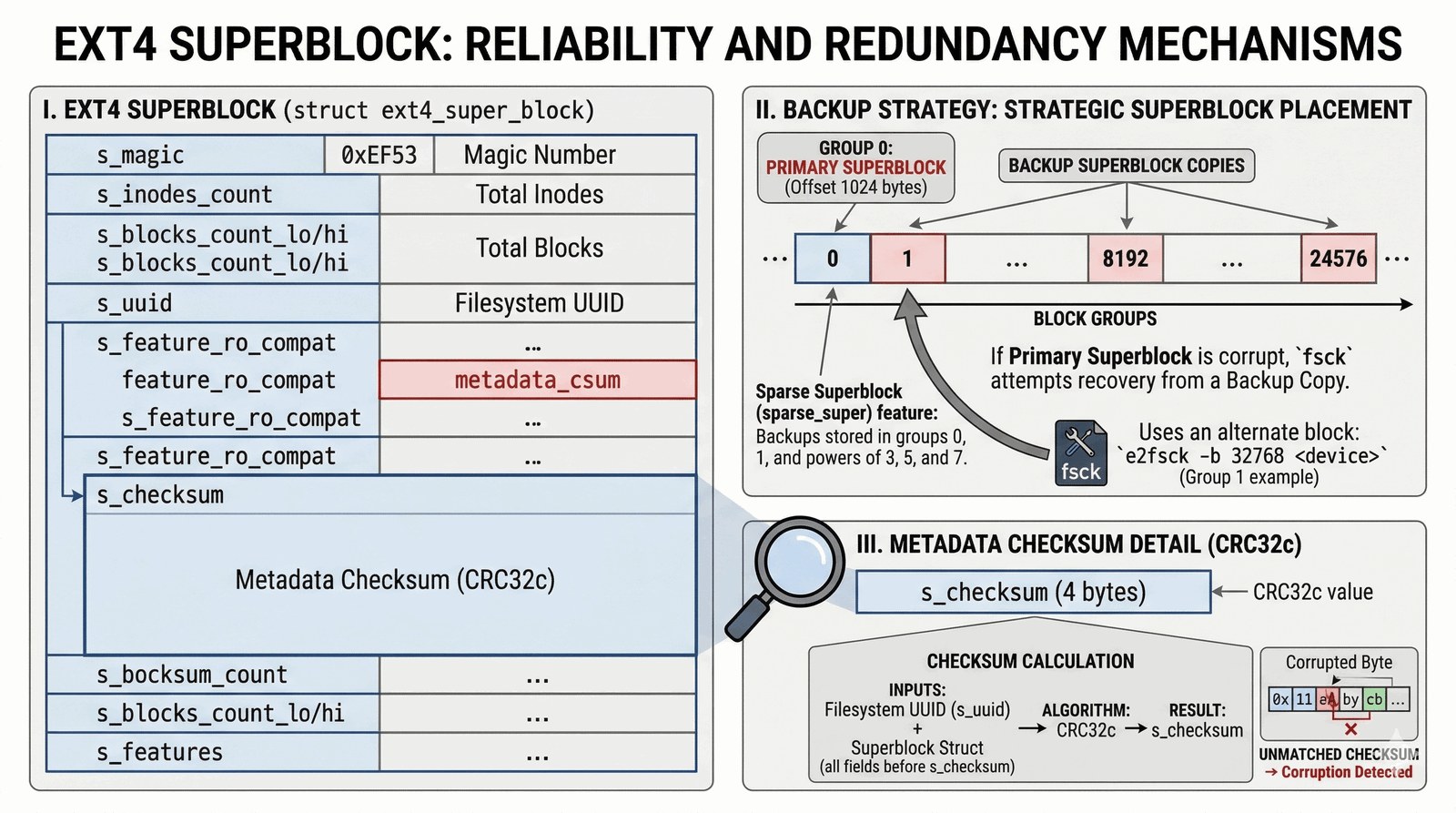
Najważniejszym elementem całej tej układanki jest Superblock. To mózg operacyjny partycji. Zawiera on krytyczne parametry: jaki jest rozmiar bloku, ile jest łącznie grup, kiedy po raz ostatni sprawdzano spójność danych oraz unikatowy identyfikator systemu plików (UUID – Universally Unique Identifier). Ponieważ uszkodzenie Superblocka oznaczałoby śmierć całego systemu plików, EXT4 tworzy jego liczne kopie zapasowe, rozrzucone w różnych grupach bloków. Jeśli pierwsza kopia ulegnie awarii, administrator może „podstawić” zapasową, ratując dane przed utratą.
Struktura typowej Grupy Bloków:
- Superblock Backup: Kopia zapasowa „mózgu” systemu (nie w każdej grupie).
- Group Descriptors: Opis stanu danej dzielnicy (ile ma wolnego miejsca).
- Mapy bitowe: Błyskawiczne tablice pokazujące, co już mamy zajęte.
- Inode Table: Tu śpią „dowody osobiste” plików z tej dzielnicy.
- Data Blocks: Tu mieszkają rzeczywiste bity Twoich zdjęć, filmów i dokumentów.
3. Mechanika: I-węzły, bloki i ekstenty
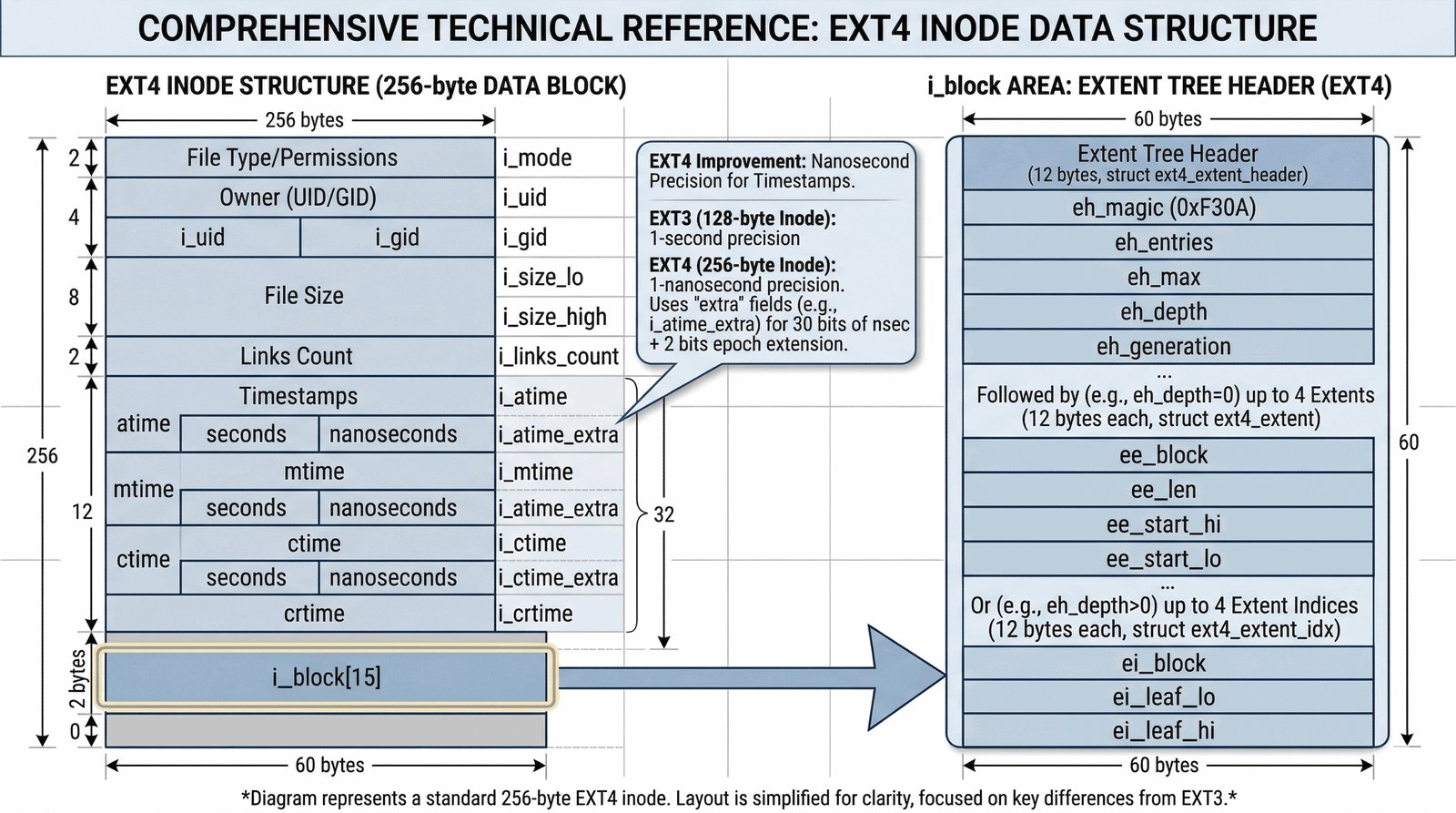
Jeśli chciałbyś zrozumieć Linuxa, musisz zrozumieć i-węzeł (inode). Inode to sformalizowana struktura danych (domyślnie 256 bajtów w EXT4), która opisuje dokładnie jeden obiekt w systemie plików (plik, katalog, a nawet gniazdo sieciowe). Co fascynujące, inode nie przechowuje nazwy pliku – przechowuje za to wszystko inne: od praw dostępu rwx, przez tożsamość właściciela, aż po precyzyjne czasy modyfikacji. Gdy edytujesz plik, Linux zazwyczaj nie zmienia struktury katalogu, a jedynie pole `mtime` w odpowiednim i-węźle.
Ewolucja adresowania: Skalowanie dla plików różnych rozmiarów
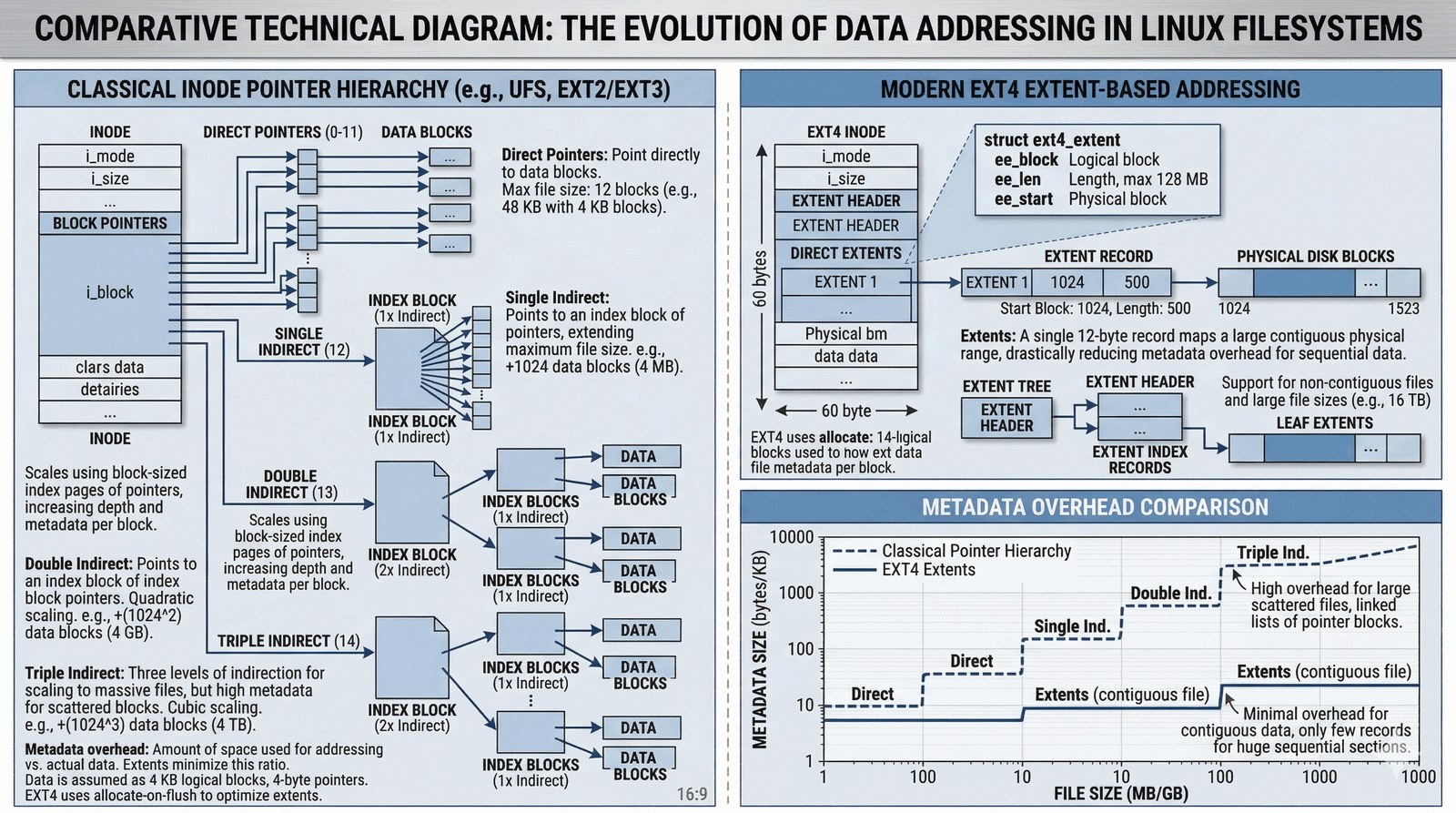
Aby system plików mógł obsłużyć zarówno malutki plik tekstowy, jak i ogromną bazę danych, musi posiadać elastyczny sposób wskazywania bloków na dysku. Klasyczny model (używany w EXT2 i EXT3) opierał się na wskaźnikach wielopoziomowych:
- Małe pliki (Wskaźniki Bezpośrednie): Wewnątrz i-węzła znajduje się zazwyczaj 12-15 wskaźników bezpośrednich. Każdy z nich wskazuje prosto na blok z danymi. Przy bloku 4 KB pozwala to zapisać plik o rozmiarze do 48-60 KB bez żadnych dodatkowych operacji wyszukiwania. To najszybsza metoda odczytu.
- Średnie pliki (Wskaźnik Pośredni / Single Indirect): Gdy plik rośnie, system używa kolejnego wskaźnika, który zamiast do danych, prowadzi do specjalnego „bloku indeksowego”. Ten blok zawiera listę kolejnych 1024 wskaźników do danych (przy bloku 4 KB). Pozwala to na pliki do ok. 4 MB.
- Duże pliki (Wskaźniki Podwójne i Potrójne): Dla jeszcze większych plików stosuje się wskaźnik podwójnie pośredni (blok pełen wskaźników do bloków ze wskaźnikami) oraz potrójnie pośredni. Dzięki temu „drzewku” system może zaadresować pliki o rozmiarach wielu terabajtów.
Ekstenty – ewolucja w EXT4
Choć model wskaźników wielopoziomowych jest genialny w swojej prostocie, staje się „ciężki” przy plikach o rozmiarze wielu gigabajtów, ponieważ system musi śledzić miliony pojedynczych numerów bloków. EXT4 wprowadza rewolucję w postaci ekstentów (extents).
Zamiast wymieniać milion bloków po kolei, EXT4 zapisuje początek i długość ciągłego obszaru. Na przykład: „ten film zaczyna się w bloku nr 5000 i zajmuje kolejne 20 000 bloków”. W jednym i-węźle zmieszczą się 4 takie ekstenty. Jeśli plik jest bardziej pofragmentowany, ekstenty same tworzą strukturę drzewiastą (B-drzewo). To drastycznie zmniejsza ilość metadanych i przyspiesza odczyt, promując ciągłość zapisu i eliminując potrzebę wielopoziomowych wskaźników pośrednich w większości przypadków.
I-węzły są alokowane statycznie podczas formatowania partycji. Oznacza to, że system od razu przygotowuje miejsce na „dokumenty tożsamości” dla Twoich przyszłych plików. Każdy i-węzeł ma swój unikalny numer w obrębie partycji. Możesz go podejrzeć poleceniem ls -i. To właśnie ten numer (a nie nazwa) jest dla systemu operacyjnego prawdziwym identyfikatorem pliku.
4. Logika: Jak Linux znajduje Twoje pliki?
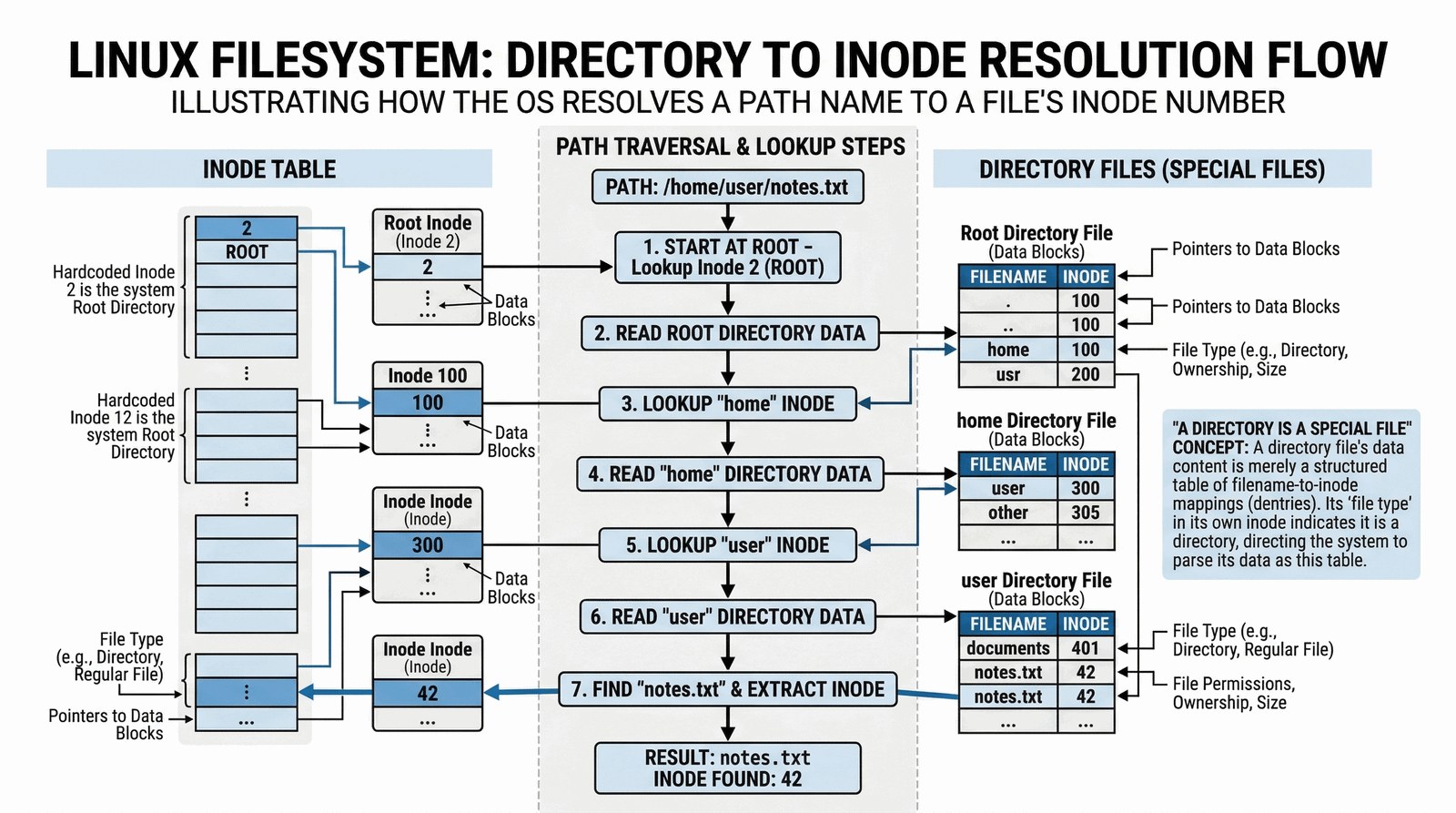
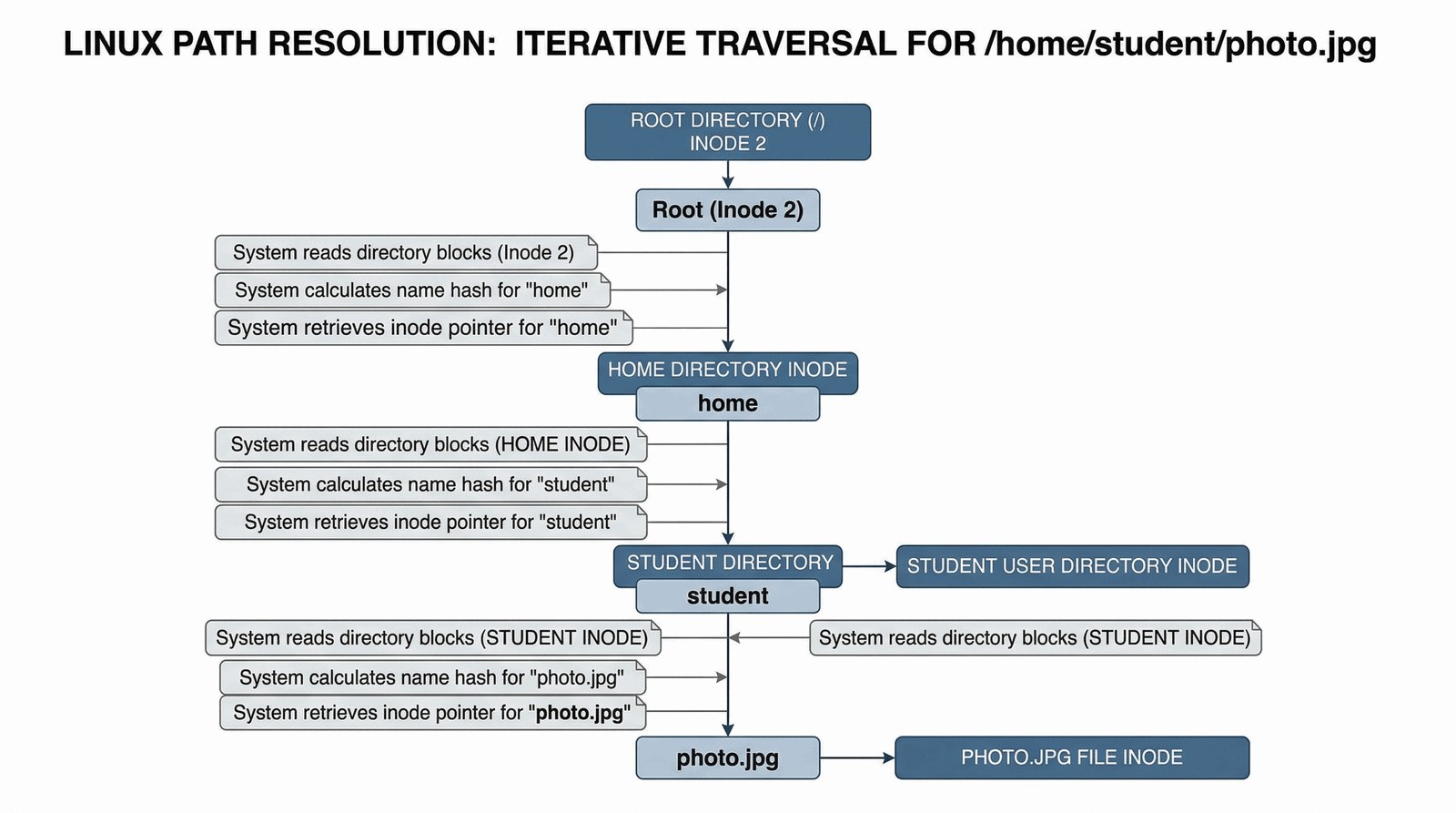
Skoro i-węzeł nie zna swojej nazwy, to jak to się dzieje, że notatki.pdf otwiera się bez błędu? Odpowiedź kryje się w katalogach. W systemie Linux katalog to specjalny plik, którego zawartością jest lista mapowań. Wpis w katalogu to prosta para: [Nazwa] – [Numer I-węzła]. Kiedy otwierasz folder w menedżerze plików, Linux po prostu czyta ten „specjalny plik” i wypisuje nazwy, które w nim znalazł.
Proces znajdowania pliku na podstawie ścieżki nazywamy rozpoznawaniem ścieżki (Path Resolution). Gdy prosisz o /home/student/foto.jpg, Linux zaczyna od katalogu głównego (root, i-węzeł o numerze 2). Czyta zawartość i-węzła 2, który mówi mu, gdzie na dysku leżą bloki katalogu głównego. Przeszukuje te bloki, by znaleźć wpis „home” i numer jego i-węzła. Powtarza to dla „student”, aż trafi na wpis dla „foto.jpg”, odczyta jego numer i-węzła i wreszcie dotrze do bloków z danymi Twojego zdjęcia. To niesamowite, jak wiele operacji dzieje się w ułamku sekundy przy każdym kliknięciu!
Dzięki temu mechanizmowi Linux obsługuje tzw. dowiązania twarde (Hard Links). Możemy mieć dwa różne wpisy w dwóch różnych katalogach (np. „moje_foto.jpg” i „kopia.jpg”), które wskazują na ten sam numer i-węzła. Fizycznie na dysku jest tylko jeden plik, ale system pozwala widzieć go pod dwiema nazwami. Plik zostanie całkowicie usunięty dopiero wtedy, gdy skasujemy wszystkie dowiązania do jego numeru i-węzła i system wyzeruje licznik linków.
5. Efektywność: Rozmiar bloku i slack space
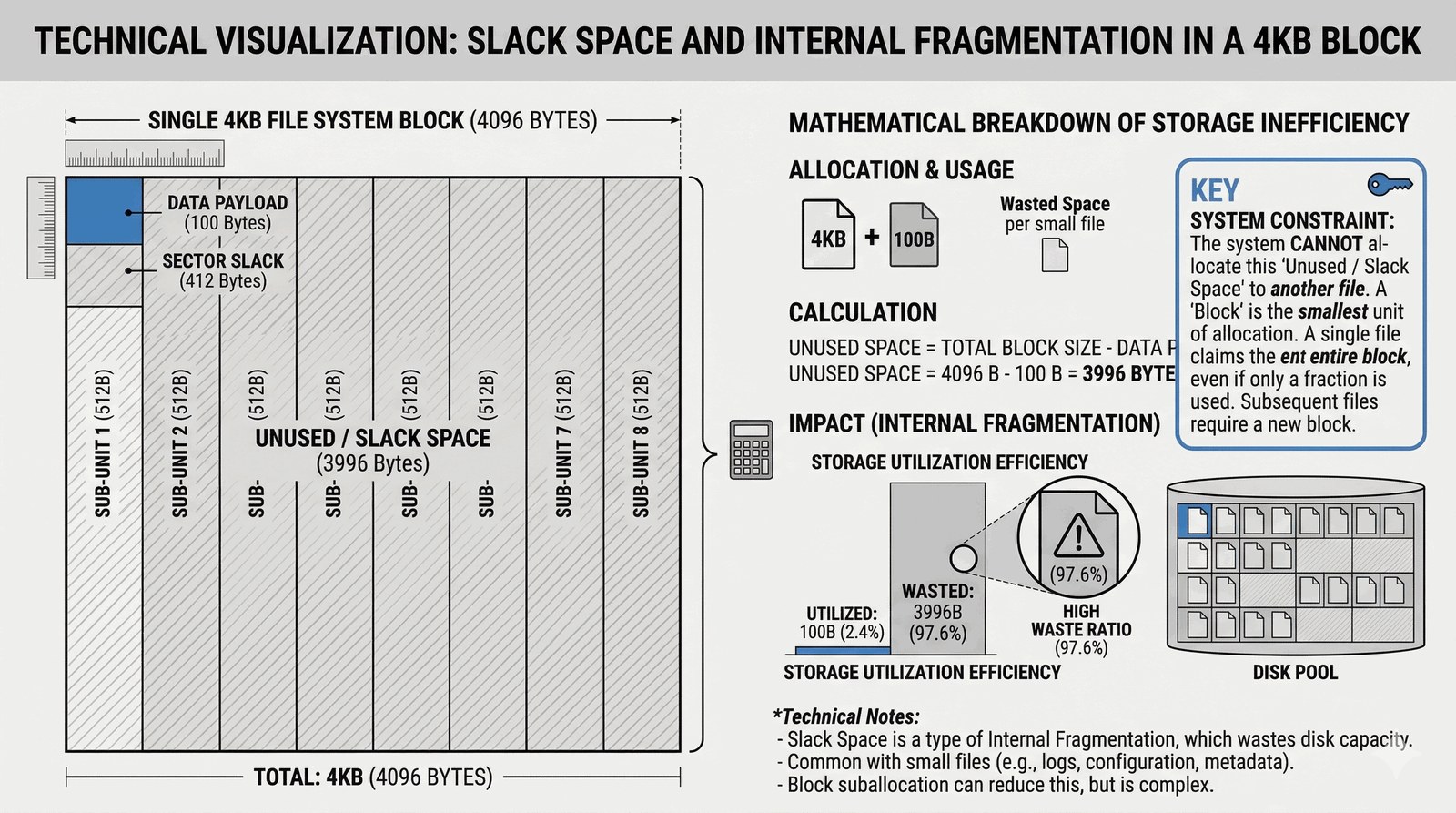
System plików operuje na atomowych jednostkach zwanych blokami logicznymi. Domyślnie w EXT4 jest to 4096 bajtów (4 KB). Dlaczego wybrano taką wartość? Większość nowoczesnych procesorów zarządza pamięcią RAM w kawałkach o dokładnie tym samym rozmiarze (tzw. strony pamięci). Synchronizacja rozmiaru bloku na dysku z rozmiarem strony w RAM sprawia, że transfer danych jest niesamowicie wydajny – system może przerzucać całe bloki bezpośrednio między dyskiem a pamięcią operacyjną bez zbędnej obróbki.
Jednak ta wydajność ma swój ukryty koszt, zwany fragmentacją wewnętrzną (slack space). Wyobraź sobie, że piszesz jednolinijkowy skrypt, który zajmuje tylko 100 bajtów. Ponieważ system plików potrafi przydzielać miejsce tylko całymi blokami, Twój 100-bajtowy skrypt „zarezerwuje” dla siebie pełne 4096 bajtów. Pozostałe 3996 bajtów to pusta przestrzeń, której system nie może dać nikomu innemu. Przy ogromnej liczbie malutkich plików (np. logi serwera lub drobne pliki konfiguracyjne), marnotrawstwo miejsca może być znaczące.
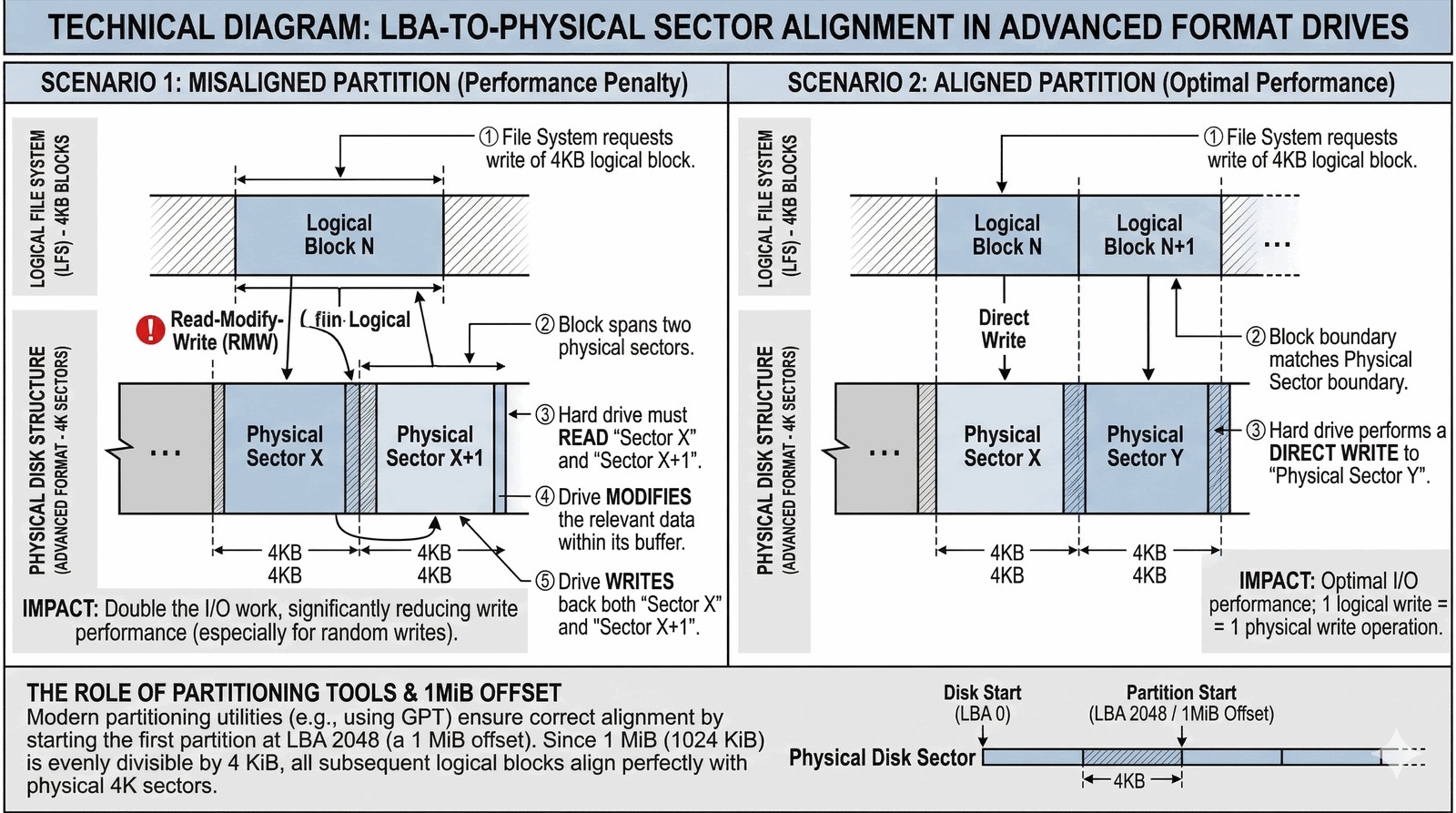
Warto też wiedzieć o istnieniu wyrównania (alignment). Nowoczesne dyski o zaawansowanym formacie (AF – Advanced Format) mają sektory fizyczne o rozmiarze 4 KB. Jeśli Twój system plików byłby źle skonfigurowany (np. bloki zaczynałyby się w połowie fizycznego sektora dysku), to każdy zapis jednego bloku wymagałby od dysku odczytania dwóch sąsiednich sektorów, zmodyfikowania ich i ponownego zapisu obu. Taka sytuacja drastycznie obniża wydajność, dlatego współczesne narzędzia partycjonujące (jak fdisk czy parted) automatycznie dbają o idealne wyrównanie początków partycji do granic 1 MiB.
6. Diagnostyka: Limity plików a miejsce na dysku
To jeden z najtrudniejszych problemów do wyłapania na początku drogi administratora: dysk zgłasza błąd „No space left on device”, mimo że polecenie df -h twierdzi, że mamy jeszcze 30% wolnego miejsca. Jak to możliwe? Otóż w systemie plików EXT4 możesz zabraknąć nie tylko „miejsca na dane”, ale i „miejsca na dowody osobiste plików”. Jak już wiesz, i-węzły są tworzone statycznie przy formatowaniu partycji.
Jeśli na Twoim serwerze gromadzą się miliony mikroskopijnych plików (np. sesje w PHP lub małe pliki typu cache), możesz po prostu wyczerpać wszystkie numery i-węzłów. W takiej sytuacji nie utworzysz już ani jednego nowego pliku, chociaż wolne gigabajty wciąż są dostępne. Rozwiązanie tego problemu po fakcie jest bolesne – zazwyczaj wymaga skasowania milionów drobnych plików lub przeformatowania partycji z większą gęstością i-węzłów. Dlatego tak ważne jest monitorowanie stanu i-węzłów poleceniem df -i.
Warto też wspomnieć o Zarezerwowanej Przestrzeni (Reserved Space). Domyślnie EXT4 rezerwuje 5% miejsca na partycji systemowej wyłącznie dla konta `root`. Cel jest szlachetny: jeśli zwykły użytkownik przez przypadek zapcha dysk w 100% (np. ściągając zbyt wiele torrentów), system operacyjny i tak będzie miał te 5% zapasu, aby administrator mógł się zalogować, przejrzeć logi i bezpiecznie usunąć nadmiar danych. Bez tej rezerwy system mógłby po prostu „zamarznąć” przy próbie zapisu jakiegokolwiek logu systemowego.


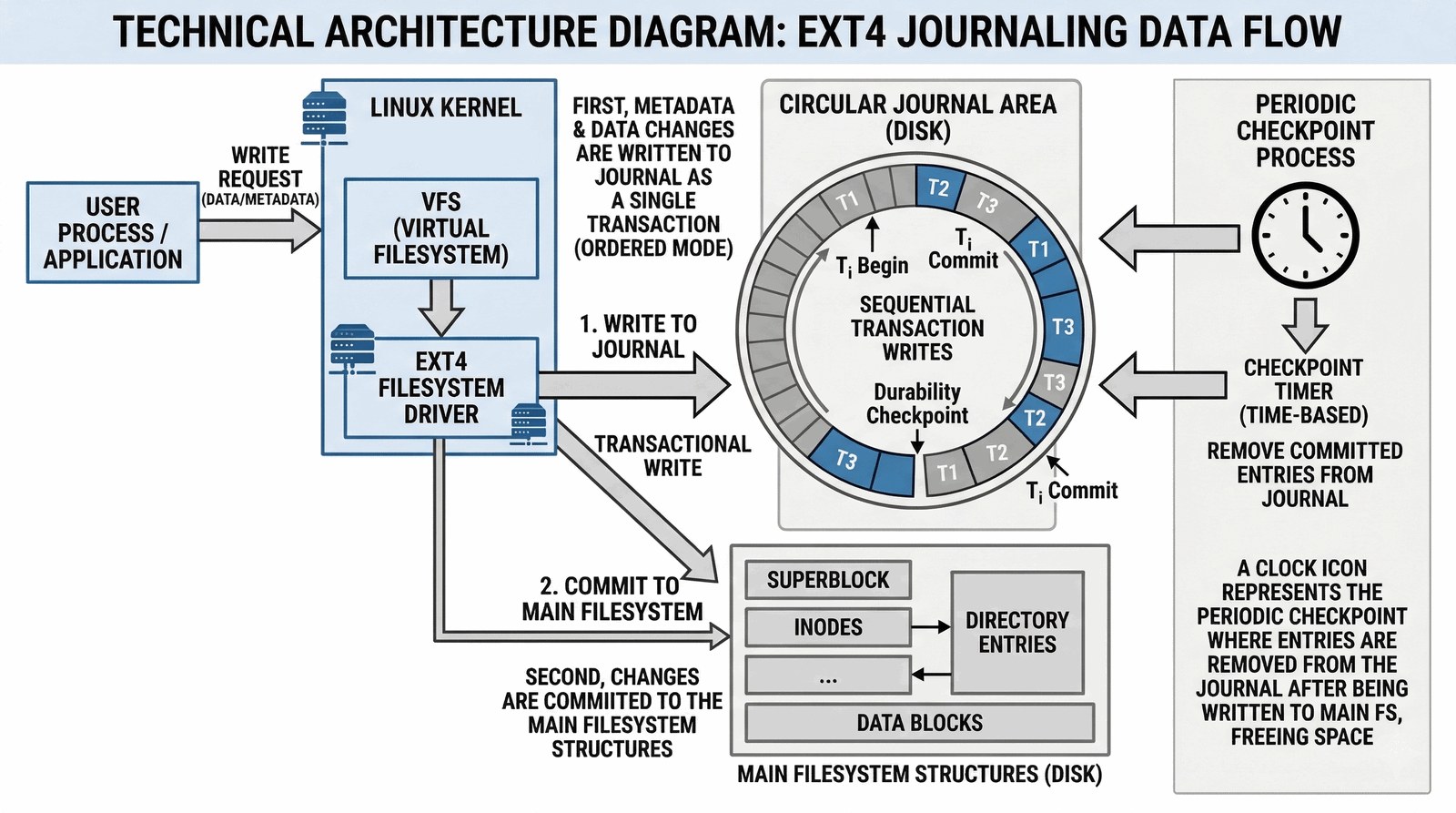
7. Niezawodność: Rola kroniki (Journaling)
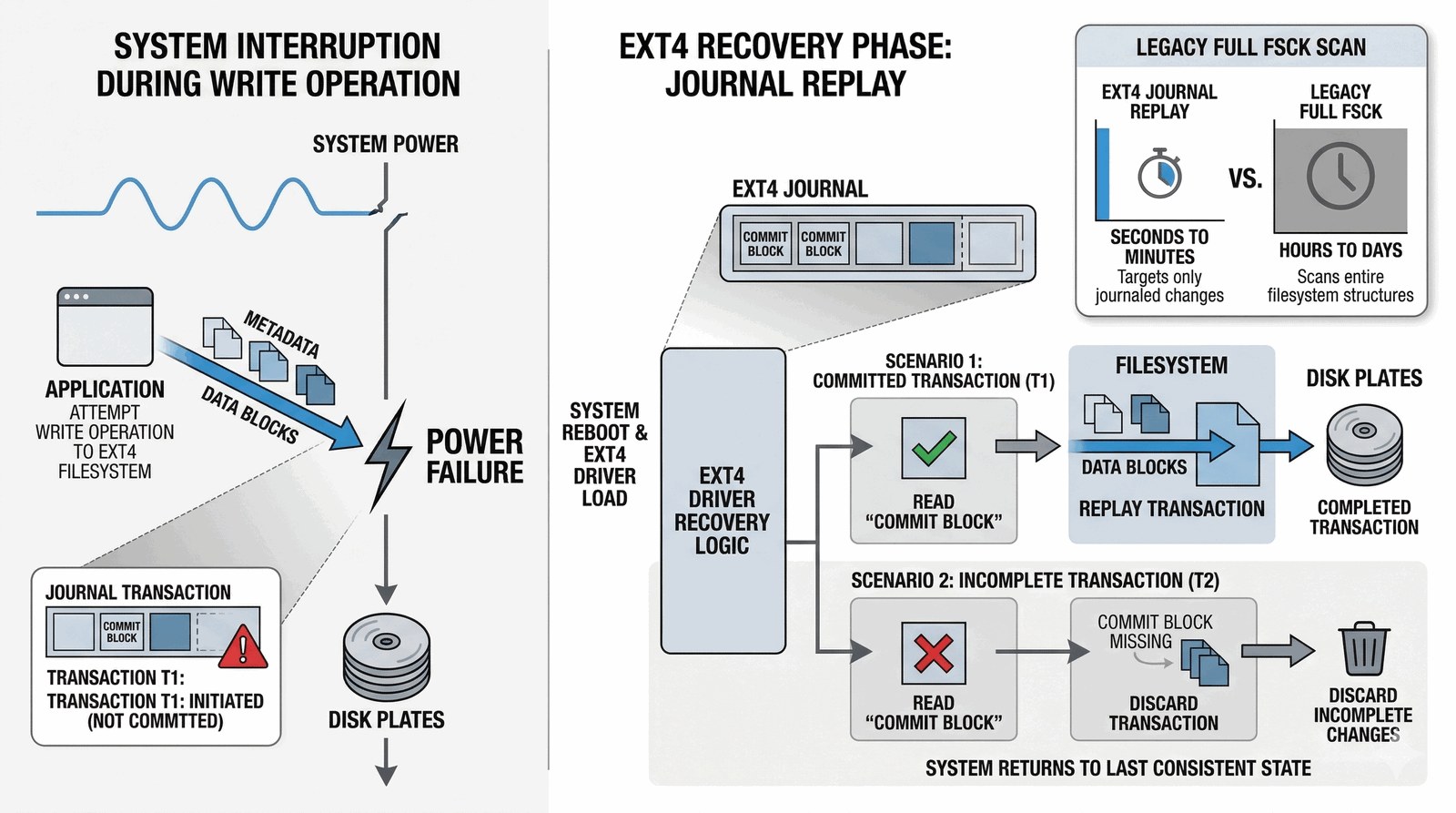
W dawnych czasach (lata 90.), nagłe wyłączenie prądu podczas pracy Linuxa oznaczało „czarną rozpacz”. System operacyjny po ponownym uruchomieniu wykrywał, że system plików nie został poprawnie odmontowany i uruchamiał program fsck (File System Check – sprawdzanie systemu plików). Na dużych dyskach takie sprawdzanie spójności mogło trwać godzinami, skanując blok po bloku w poszukiwaniu błędów. EXT4 rozwiązuje ten problem za pomocą mechanizmu kronikowania (Journalingu).
Kronikowanie działa jak „dziennik pokładowy” kapitana. Zanim system dokona jakiejkolwiek zmiany (np. zapisania nowej porcji danych w pliku), najpierw zapisuje skrótowy opis tej operacji w specjalnym, ukrytym pliku kroniki. Dopiero gdy kronika potwierdzi „przyjąłem zlecenie”, system przystępuje do właściwego zapisu na dysku. Jeśli w tym krytycznym momencie zabraknie prądu, po restarcie Linux po prostu patrzy do kroniki. Jeśli operacja nie jest oznaczona jako „zakończona”, system ją wycofuje lub ponawia w ułamku sekundy. Dzięki temu system plików wraca do spójnego stanu niemal natychmiast po awarii.
EXT4 oferuje trzy poziomy bezpieczeństwa kronikowania. Domyślny tryb ordered to złoty środek: pilnuje tylko metadanych, ale dba, by dane trafiły na dysk przed wpisem do kroniki. Jeśli zależy Ci na maksymalnej szybkości kosztem bezpieczeństwa, możesz wybrać tryb writeback, który kronikuje tylko metadane bez gwarancji kolejności zapisu danych – operacje mogą się „wyprzedzać”, co w rzadkich przypadkach awarii może pozostawić ślady w danych. Możemy jednak wybrać ekstremalny tryb journal, który kronikuje absolutnie wszystko (nawet treść plików), co daje pancerną odporność na awarię, ale drastycznie spowalnia dysk, bo każda operacja musi być zapisana fizycznie dwukrotnie. Wiedza o tym, który tryb wybrać, odróżnia administratora amatora od profesjonalisty projektującego serwery bazodanowe.